Why AI will not doom us all
We've all seen it - AI, and LLMs specifically, are all over the place, even in ovens and computer mice. More people than ever are actively working and researching in this field. There is a huge hype around the future of AI and every business wants to integrate with it. But is this hype justified? Or are these only marketing buzzwords?

Definitions
Let’s start by using the correct terms and understand what they mean.
- Artifical Intelligence (AI) is an umbrella term that describes many strategies and techniques to make computers humanlike.
- Machine Learning (ML) is a branch of AI based on statistical algorithms and models. It works by identifying patterns in large data sets and then use them on new, unseen data.
- Deep Learning is a subset of ML that implements neural networks, a model that vaguely resembles biological neurons in our brain, to make decisions.
- Natural Language Processing (NLP) is a branch of AI focused on making human communication comprehensible for computers.
- Large Language Models (LLMs) are very large deep learning models specialized in natural language processing (NLP) tasks. They use common language, such as English, as input and output for their operations.
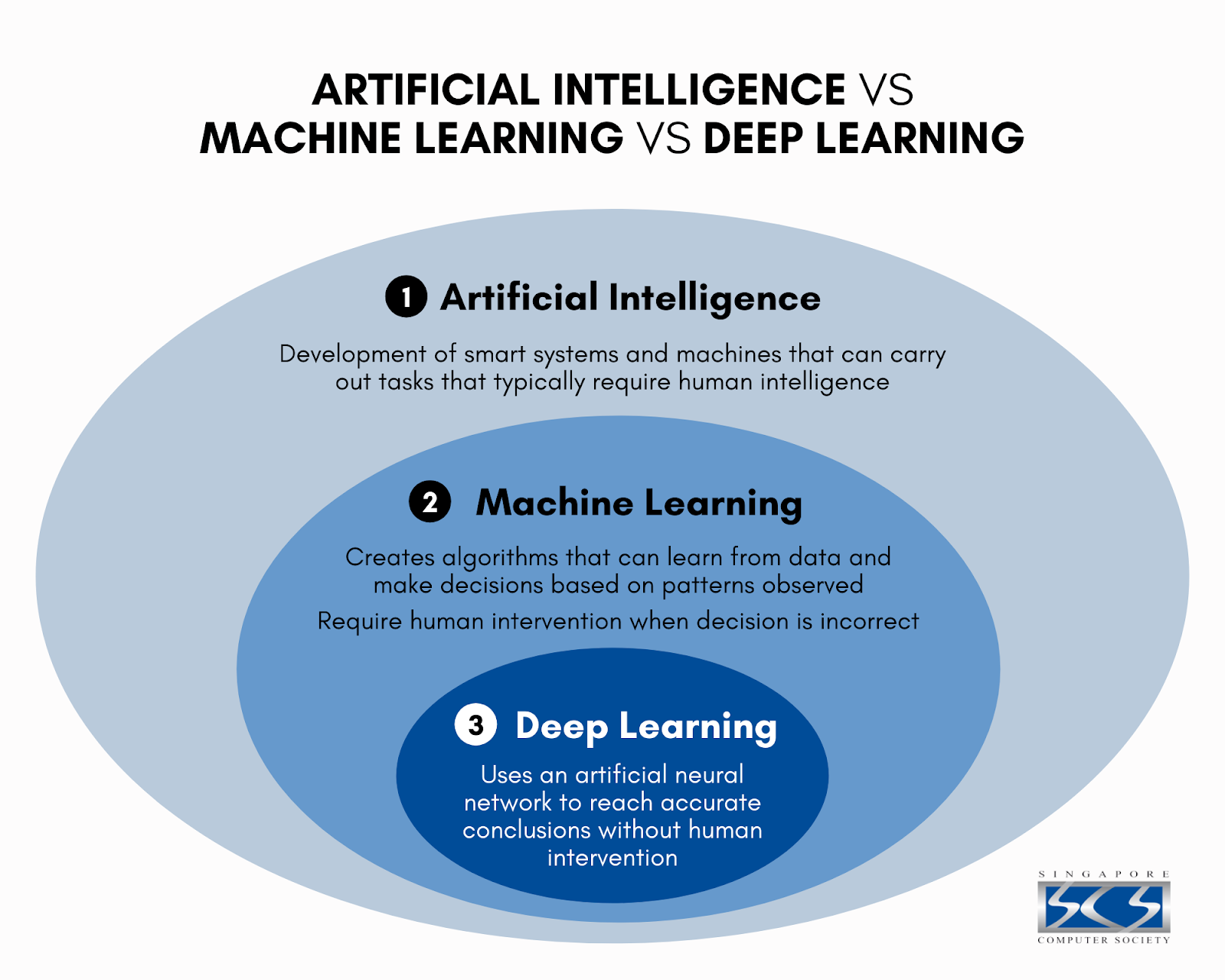
Image from Singapore Computer Society
LLMs are just a small part of the entire field of AI. There are many other AI algorithms that are commonly used that have nothing to do with LLMs. AI is a much bigger field, from NPC in videogames to programs that recognize faces and objects. To better understand these differences, let’s briefly talk about the history.
History of AI
Artificial intelligence research started way back in the ’50s with Alan Turing, the father of modern computer science. The first AI algorithms were written in 1951, to play checkers and chess.
Many important mathematical papers were written in the ’60s, describing the neural network approach. There was a wave of optimism already back then: in 1965, researchers wrote that “machines will be capable, within twenty years, of doing any work a man can do”, and in 1970, “In from three to eight years we will have a machine with the general intelligence of an average human being” (source). The field was heavily financed by investors.
There was no actual impressive AI product at the time - programs could only solve trivial problems, and results hoped by the investors weren’t in sight. Funds were cut. AI research was heavily limited by computing power and lack of training data.
This cycle of optimism and crisis repeated in the ’80s, as AI became mainstream. Some impressive progress was achieved, such as in 1997, when Deep Blue became the first program to beat the world champion at chess, although this was not due to some revolutionary paradigm, but mostly on the increase in speed and availability of computing power. The investment didn’t pay off, so funds were cut once again.
Nowadays, AI is now more accessible than ever, with open source projects that allows anyone to practice and make programs with it. Computing power and data is cheap and available, there has never been a better time to be interested in AI than today.
How LLMs (such as GPT) work
GPT stands for Generative Pre-Trained Transformers - a specific type of neural network based on a paper from 2017, Attention Is All You Need. This paper describes a new architecture to solve NLP tasks.
Basically, GPT is a sophisticated prediction algorithm for the next word, such as the one in most phones’ keyboard. For each word that you type, it tries to guess what the next word is, based on patterns that it has learned.
For example, after typing the word “Barack”, it’s extremely likely that the next word will be “Obama”, simply because “Obama” immediately follows “Barack” in the vast majority of the train data that it has seen.
The main difference between your phone’s prediction algorithm and GPT is context. GPT chooses the next word not just by the previous one. It analyzes the entire conversation up to that point. This is the attention mechanism that the paper presented.
In other words - GPT actively trains and modifies itself to best suit the current conversation and keep the output relevant. This is what makes GPT really powerful and versatile.
This approach has proven to be quite successful, but it requires huge amounts of data and computing power to train these models. But that might not be all that is needed…
Diminishing returns
LLMs are great at answering questions they have seen. But the moment something more specific is asked, they tend to hallucinate and make mistakes. That’s because they were not explicitly trained for that task, for that scenario.
The hope is that, by adding more and more data, there won’t be the need to consider all possible scenarios, because the AI will find the patterns and figure out the answer by itself. By extrapolating patterns from a huge amount of data, it will develop general intelligence (AGI), thus being able to reason, plan, and learn from its mistakes, answering questions even if it was not specifically trained for that (Zero Shot Learning). But is this sustainable? Can this approach be used to keep improving over time? Or does it have a limit?
A paper discusses this problem and analyzed the zero-shot performance of 34 models with 5 datasets. Their conclusion is that the zero-shot performance of current LLM models follows a logarithmic trends, growing really slowly and requiring exponentially more data for a meaningful increase in performance, rather than a linear correlation.
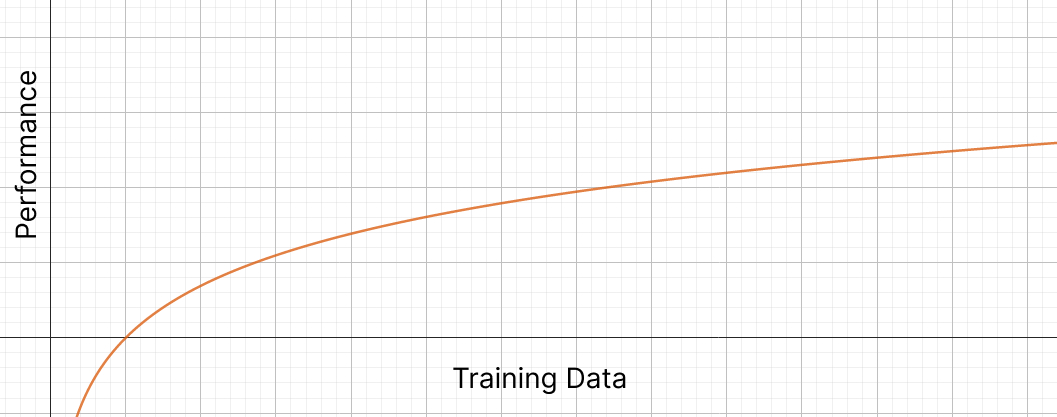
Training AI is extremely expensive - billions of dollars expensive. Is it worth it to spend that much money only for a 1% improvement? Will investors keep pouring money into the field, without any meaningful progress to back it up? If history repeats itself, the answer is probably no.
With the current architecture, we might hit a plateau, where data and computing power are no longer the bottlenecks. Making meaningful improvements may not be worth it. This trend is already showing in many recent AI startups.
The AI bubble
The current phase might be similar to the dot-com bubble of the late ’90s. The sudden growth of internet led to the creation of many startups that were over-hyped and later crashed, hurting the entire economy as investors were too reckless to invest into the technology.
stability.ai
stability.ai is a startup made in late 2020 that created an open-source image generation model called Stable Diffusion. They raised hundreds of million of dollars of valuation after the release. They have ambitious visions for the future, improving their AI to the benefit of humanity.
They had huge expenses and debts that they couldn’t pay due to the cloud computing resources necessary for their research. Nevertheless, the company kept making promises they knew they couldn’t make. They tried raising another investment round, but only achieved a small part of it. Many senior leaders in the company resigned due to the disorganization of the CEO. In March 2024, the CEO was forced to step down and leave the company. The company is now in crisis, as they burn money much faster than they generate revenue, and may go bankrupt.
Inflection
Inflection is an AI startup made in 2022 that managed to raise 1.5 billion dollars from investors to develop their main product, Pi, an AI assistant to help people with emotional support. It struggled to gain traction with consumers, and in less than a year many key members of the company left to join Microsoft. The company is now an AI studio to help businesses integrate with LLMs, a shell of their original idea.
Cohere
Cohere is a Canadian AI startup made by some of the Google researcher that published the Attention Is All You Need paper, the basis of most modern LLMs today. They’ve attempted to develop an enterprise chatbot, allowing businesses to integrate with AI with customizable and cheap models. They raised 445 million dollars, but brought only 13 million dollars of revenue last year, even though their valuation is 6 billion dollars. Their product is gaining traction, but the data shows unclear economics about their business model that just might not be worth it.
The Gartner hype cycle
We might be in the peak of inflated expectations of the Gartner hype cycle. The peak of inflated expectations is when product usage increases, but there’s still more hype than proof that the innovation can deliver what you need.
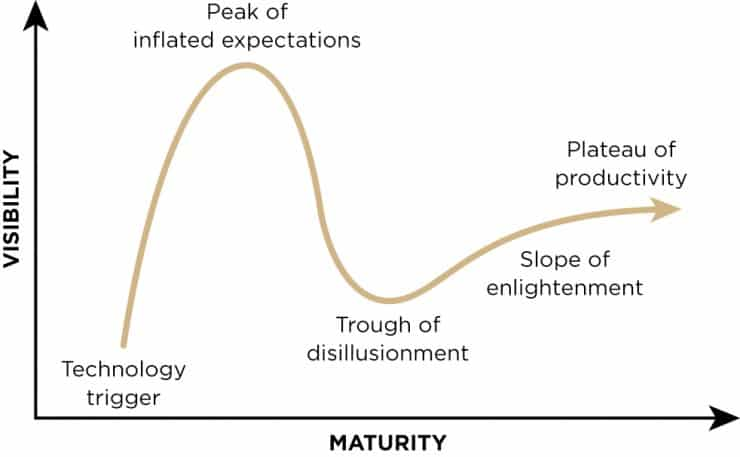
People may have an overly-optimistic idea of AI and its current capabilities. The current LLMs might not limited by the computing power or the amount of data, but by their architecture. The attention mechanism, although really clever, might have some limits that make it extremely hard to process further and reach general intelligence, if it can even be reached, that is.
Conclusion
AI is definitely here to stay, and it’s a great tool to boost productivity. But it probably won’t evolve into a dystopian future where machines take over humanity - and it won’t replace doctors, programmers and other specialized skills. People are notoriously bad at predicting the future - where are the flying or the self-driving cars? AI might just be the next addition to the list.
The current transformer architecture might be limiting the performance, and GPT-7 may not be that much better than GPT-4. Or perhaps it’s the next big thing that will change humanity. After all, people were saying that “internet was just a fad” in the year 2000.
In either case, it’s an exciting time to be alive! Let’s see if this article will age like milk or wine!
This article was NOT written with AI :)